今年的 GopherChina 大会如期而至,没能亲临现场,但是 keynote 绝不会错过。一如往常,谢大第一时间放出了今年的keynote。今年的 keynote 中有不少老面孔,不知道以后大会是否会把固定若干老面孔作为惯例。如果你错过了去年的 keynote, 可以参见鄙人拙文《GopherChina 2018 keynote 点评》。
整体上,今年的演讲主题跟往年所涉及的领域和覆盖的范围区别不大,无论你是关注架构、微服务、语言细节,还是数据库、存储、业务及应用系统构建,都能从中找到自己感兴趣的内容。
1.1 大型微服务框架设计实践 – 杜欢
如果你曾经想用比较hack的方式获取goroutine id, 那么你有很大可能性使用过杜欢的goroutine. 也因为写Golang 获取 goroutine id 完全指南的缘故,跟杜欢结识。看到这个keynote,心里还是有种从未谋面,但是久违的熟悉感。在大概3年前,我其实也做过类似的框架设计和开发。很多理念和原则的确是 cant't agree more. 其中,“框架和业务正交”的原则也是充分发挥了golang自带的正交特性。
在框架中,隔离层的思想很朴素,但是很实用。我曾经因为在设计之初没有引入隔离层,自己手动修改了多个数据库驱动库,以满足框架某个特性的引入。如今想想,真的是血与泪的教训。
1.2 用Go打造Grab的路径规划和ETA引擎
不得不感慨,Grab 的业务才是真的大型生活类服务。从形态上看,已经约等于国内滴滴+美团+顺丰组合了。演讲内容偏向算法。对地图路径规划(无论是游戏地图还是现实地图)感兴趣的同学,可以看看算法到实际工程落地之间的gap如何弥补和解决。
1.3 Go practices in TiDB – 姚维
印象中,PingCAP 出来的speaker分享质量一直都挺高。姚维老师的这次分享也保持了PingCAP一如既往的高水准,深入浅出,以小见大。一直比较好奇TiDB这种对软件质量要求极高且分布式的领域是如何做测试的,看了其Schrodinger 和 gofail 的介绍,无论从主观体感还是技术信赖都TiDB加分不少。failpoint 在实现层面是基于golang AST 做的,编译时被转换为一个 IF 语句,整体设计简单直接有效,是我喜欢的风格。
另外一个比较有意思的点是使用 chunk 来优化内存使用。以前只知道使用整块连续的内存分配策略比碎片化的内存分配更有效率,但是不知道连续内存带来的矢量化执行优势。如果你是做高性能数据库的,这个点一定不能不知道。
1.4 Testing; how, what, why – Dave
Golang官方人员 Dave 大胡子老师出品,必属精品。关于golang如何做测试的资料,看这一个就够了。
1.5 Go 业务开发中 Error & Context – 毛剑
在 golang 1.x 中,错误处理一直是一个不太舒服点。因此才有去年 Rethinking Errors for Go 2 对golang 2.x 错误处理的预览和展望。但是,golang 2 是没有具体时间表的,当前阶段,如果你在实际业务系统中对错误处理有疑惑,可以看看毛剑的处理方式。
Context 其实算是一个老生常谈的话题了,但是毛剑总结了很多实际使用中的最佳实践,分享内容还是诚意满满的。
1.6 Go并发编程实践 – 晁岳攀
从源码级别探究Go在并发层面的基础库实现。跟去年的深入CGO编程一个风格,内容非常全面和丰富,有细节有深度。如果想深入golang源码,一定不可以错过。
1.7 百度APP Go 语言实践 – 陈肖楠
从ppt内容看,算是一个大厂在小场景的golang实践。涉及的问题,以鄙人浅见:使用golang落地1年以内的创业公司都会遇到。给出的解决方案和踩过的坑已经远看不到国内巨头的风范了。如果百度再被扣上技术不行的标签,那就是哪都不行了……
1.8 Golang to build a real-time interactive SaaS Cloud – 董海冰
golang 在 WebRTC 场景下的工程实践。以前对 WebRTC 比较模糊,细致看了分享内容以后,才发现这块的内容和涉及的技术如此广博。前端时间,提供视频会议解决方案的 zoom 上市了,日后我们应该有很大概率看到更多 golang 和 WebRTC 的落地方案。
2.1 基于MINIO的对象存储方案在探探的实践 – 于乐
作者用 golang 撸了一个支持多集群的分布式对象存储系统。有两个技术细节值得技术投资和持续关注:
- Reed-Solomon,一种低冗余,高可靠的纠删码。golang 版本的实现可以参见reedsolomon.
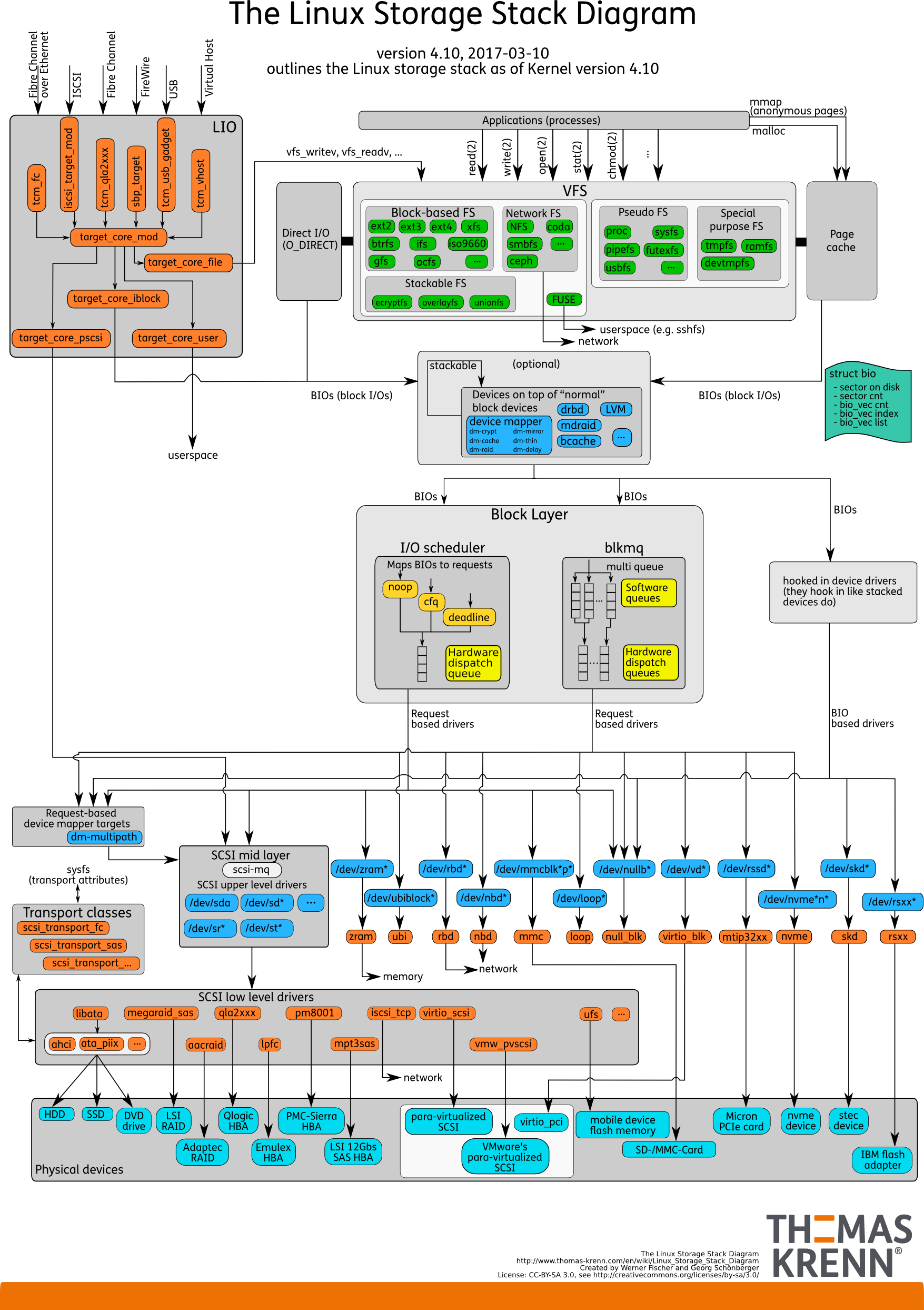
- The Linux Storage Stack Diagram. 能让你系统全面的了解 IO,并且知道 Direct IO, page cache 的本质。
2.2 从零开始用 Go 实现 Lexer & Parser – 何源
作者编译原理的底子还是在的。想当年,我们该课程的期末课程设计就是编写一个编译器。不过大部分时候,如作者所言,如果不是万不得已,不要自己写 parser. 毕竟,在不使用正则表达式的前提下,golang 提供了非常完善易用的 AST 基础库支持。
2.3 高性能高可用的微服务框架TarsGo的腾讯实践 – 陈明杰
golang和微服务经过这几年的演进发展,无论是基础框架还是周边生态,已经达到了水乳交融的程度。鹅厂的这个实践从当前时间点看,没有什么亮点,更没有什么突破。本以为会有一些 service mesh 方面的尝试,但是比较遗憾,这方面从分享内容看还走得比较靠后。
2.4 闪电网络—BTC小额支付解决方案 – 方圆
不知道这个方圆老师跟去年代表罗辑思维做分享的speaker是不是同一个人?如果是的话,真的是选错了行业风口呀。币圈有风险,跳巢需谨慎。
2.6 用Go构建高性能数据库中间件- 徐成选
一个使用golang打造中间件的实践。文末提到了一些优化方案和细节,挺受用。
2.7 花椒直播基于golang的中台技术实践 – 周洋
周洋老师也是老面孔了,第一次出现在gopher大会应该是大表360做IM长连接的分享。听那一次分享自己几乎是跪着听完的,因为在那之前自己要解决的问题和场景跟其非常类似,只是碍于当时的人手和自己的技术栈储备,我没能做出周洋那样的方案和架构,而是用了一个比较trick的方案。晃眼间,4年过去了,周洋对于中台的思考又给了自己很多启发。感谢 GopherChina 这样的平台,感谢周洋老师的分享。
2.8 知乎社区核心业务 Golang 化实践 – 杜旭
作者分享了知乎从 python 迁移到 go 的历程。巧合的是,三年前,我们也做了同样的事情,同样是从 python 迁移到 go. 不过作者有几点做得比当时的我们更好:
- 在接口验证环节上,我们当时希望靠尽可能覆盖全面的单元测试和QA验证来保证;知乎在额外还引入了python和go版本的接口交叉校验。test case的丰富和覆盖程度应该比我们当年更好。
- 引入了静态代码检查。如果用强类型语言不适用静态代码检查,那么就损失了强类型语言一般的优势。道理都知道,但是碍于当时CI/CD流程不够完善,我们这个环节一直是缺失的。
注意
以上内容只是看完keynote以后的个人观感。因为没有去现场,细节肯定有所缺失,有些观点也未必跟现场同学的反馈吻合。希望后面放出大会现场视频以后,自己能够进一步完善以上内容。








{kind=link}